提供給新手的參考筆記,流程說明與參考程式碼,練習範例取得成就感。
文章溝通對象
距離上一篇分享給非程式背景朋友的爬蟲說明文章,認識網路爬蟲:解放複製貼上的時間整整一個月。
這中間想了很多種版本,決定把內容的溝通對象放在「了解Python3基本語法、會使用pip安裝套件」的爬蟲新手,希望讓完全沒概念的朋友有基本的認知,文末也會附上適合新手參考的後續資源。
如果電腦沒有安裝Python,也可以參考瀏覽器內的爬蟲初體驗,是本文的簡化版。
我並不是工程師,但作為輔助技能,相信你跟我一樣會找到地方發揮的!
爬蟲眼中的世界
我們透過瀏覽器所看到的網頁呈現,跟爬蟲所看到的並不同,他們看的是網頁原始碼。
舉個例子,就像我們走進便利超商,拿起架上的三明治,我們會看到肉片、蔬菜以及吐司,非常直觀地出現在眼前;但是爬蟲看得比較像是標籤上的說明,例如鈉含量、卡路里等等抽象純文字的說明。
打開任一網頁,按右鍵,選擇檢查網頁原始碼,再想想我剛剛的舉例,有個印象即可。
但為了節省寶貴的時間,文章重點我會錄短片給你看。範例是我之前練習網頁的虛構內容Perfect Match。除了首頁的可愛貓咪外,其他按鈕不會出現任何反應:
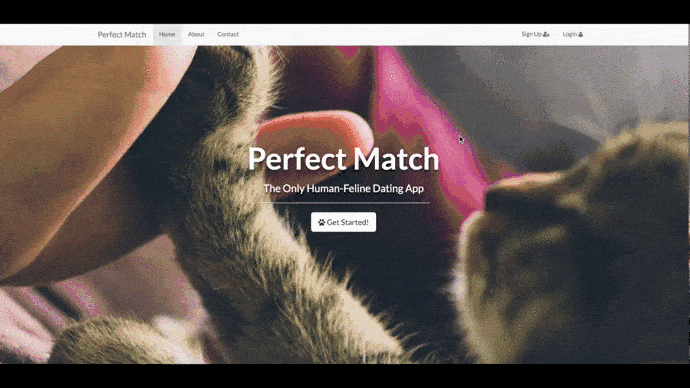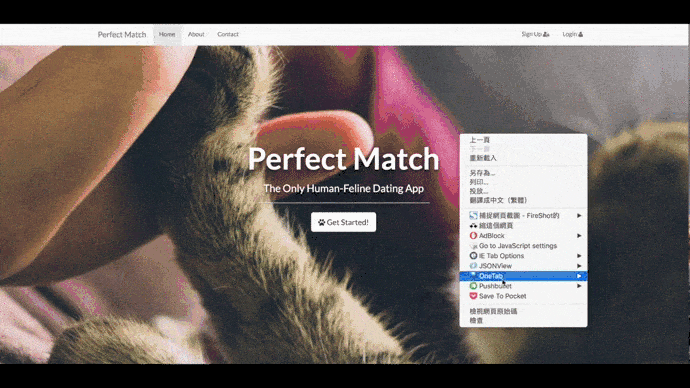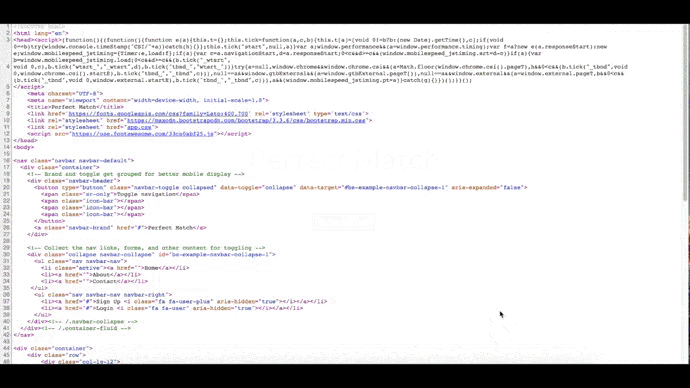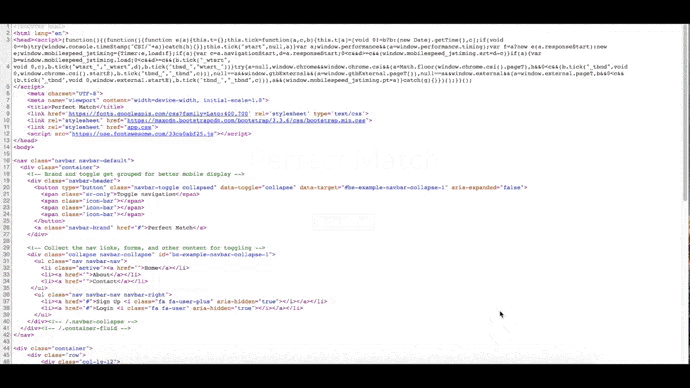
JavaScript開關檢查
但並不是所有的網頁內容,在右鍵的檢查網頁原始碼中都會看到。
網頁是由HTML、CSS、JavaScript所組成。
沒概念也不用緊張,想像你眼前有個漂亮的玻璃展示櫃,裡面按照一定距離排列了許多公仔,每個公仔各自被展示燈所照著。而櫃子旁的牆壁上,有三個開關,旁邊分別寫著HTML、CSS、JavaScript,而我們可以試著切換JavaScript的開關,看所要觀察的對象,燈是否熄滅了。
燈熄滅就表示,不打開JavaScript開關,我們就無法觀察到這個物件。
推薦使用Chrome套件:Quick Javascript Switcher,安裝完成後右上角會出現圖示。
以PChome線上購物為例,搜尋iPhone後的商品列表,每個標題都有「iPhone」關鍵字;但是如果以爬蟲的視角,在網頁原始碼中,用搜尋是找不到「iPhnoe」關鍵字的。
原因在於該網頁的完整呈現,需要開啟開關。
下列短片中,可以看到我關閉後,商品標題就消失了:
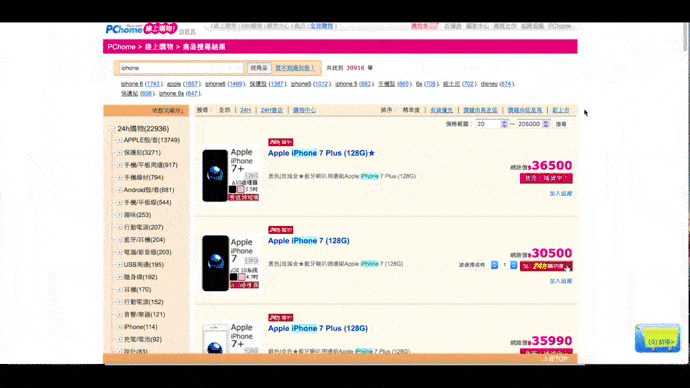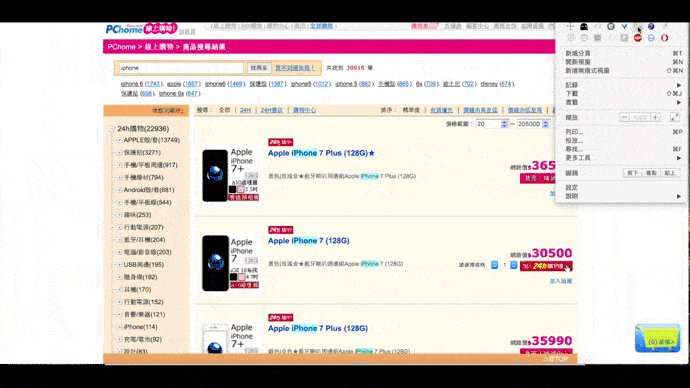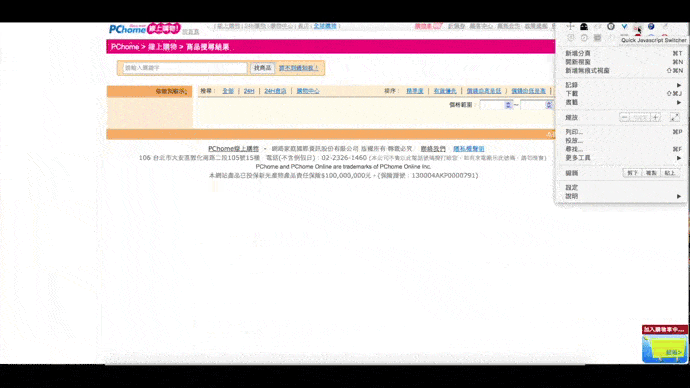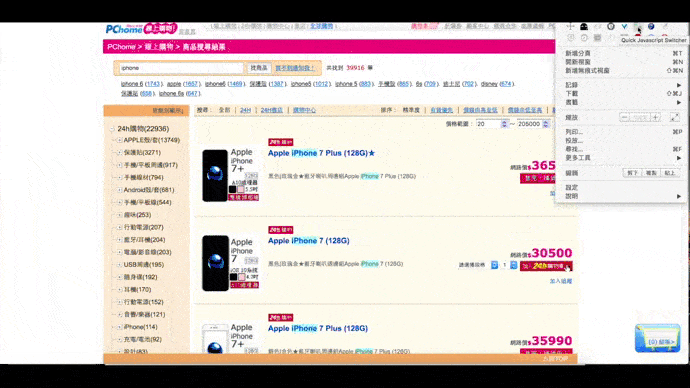
所以我們要考慮所要抓取的內容是否使用了JavaScript渲染,決定對應的方式。
安裝套件
分別是處理一般需求的pip3 install requests、模擬瀏覽器執行的pip3 install Selenium、以及元素選擇器 pip3 install beautifulsoup4。
範例:消失的文字
我做了一個簡化後方便說明的網頁:消失的文字。
同樣用Quick Javascript Switcher觀察關閉前後的變化:
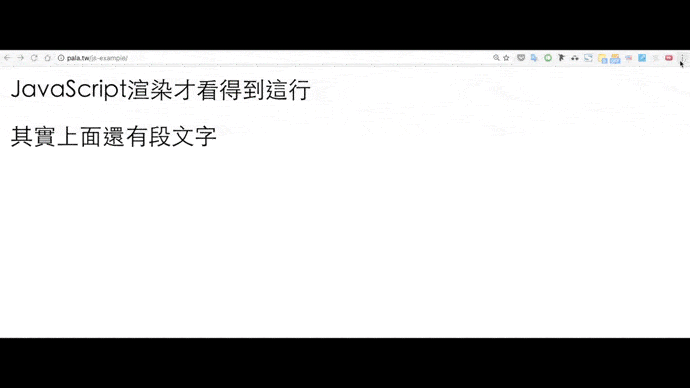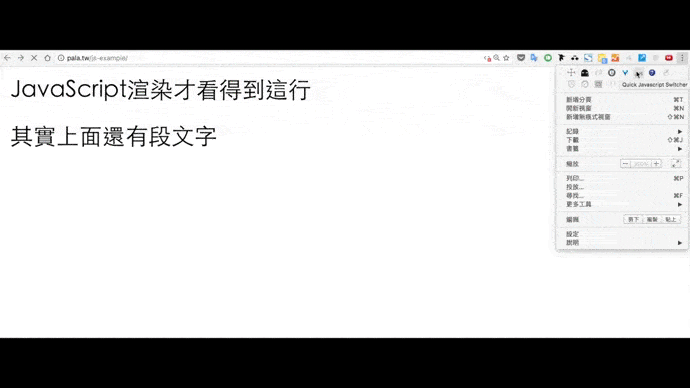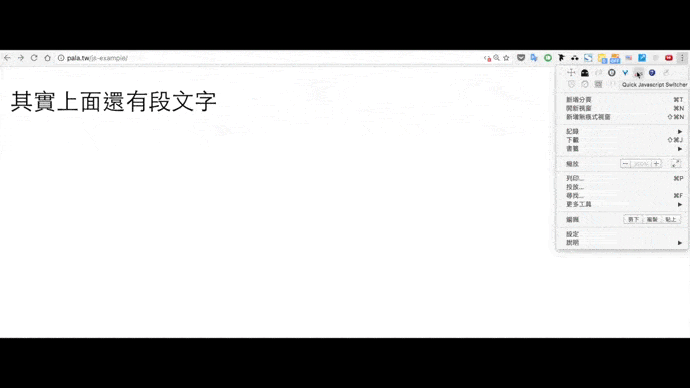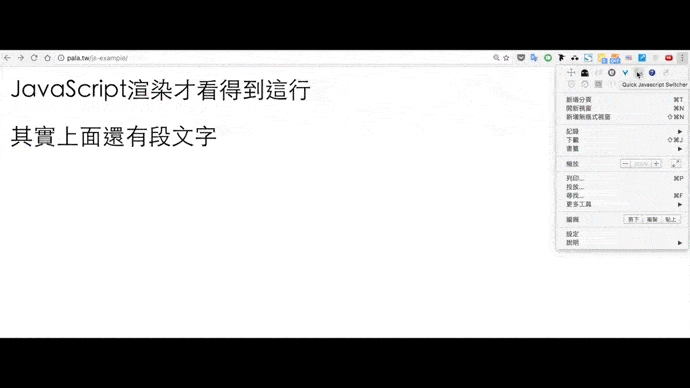
由此帶出兩個方向。
關閉JavaScript,不影響資料存在的起手式
使用套件requests,也是獲取網頁原始碼最常使用的套路:
import requests
res = requests.get('請輸入網址')
print(res.text)把網址放入:
import requests
res = requests.get('http://pala.tw/js-example/')
print(res.text)最上方的那行並沒有顯示出來:

關閉JavaScript,資料消失的起手式
為了看到JavaScript渲染結果,換成套件Selenium模擬瀏覽器執行,請下載PhantomJs(已暫停開發)或是其他瀏覽器,例如Google Chrome Driver。在程式執行的時候,Selenium會透過後者瀏覽網頁。
聽起來略為抽象是正常的…欸欸這邊請不要跳過。
請想像成你眼前的空白牆壁有一堆塗鴉,但是有些地方筆畫不連貫消失了,必須戴上特製的眼鏡才看得到完整的內容。PhantomJs這副眼鏡的好處是執行快速,馬上可以看到成果;Google Chrome Driver的特色則是他會用縮時攝影的方式,從消失的地方看起,執行一段時間才顯示完整內容。
也就是說,PhantomJs會在背景後執行,消耗較少資源,直接呈現結果;而Google Chrome Driver則是真的會開啟瀏覽器,逐步執行指令,例如在搜尋欄位輸入文字、選擇特定區塊,每個步驟都完整呈現在你以前。
套路如下:
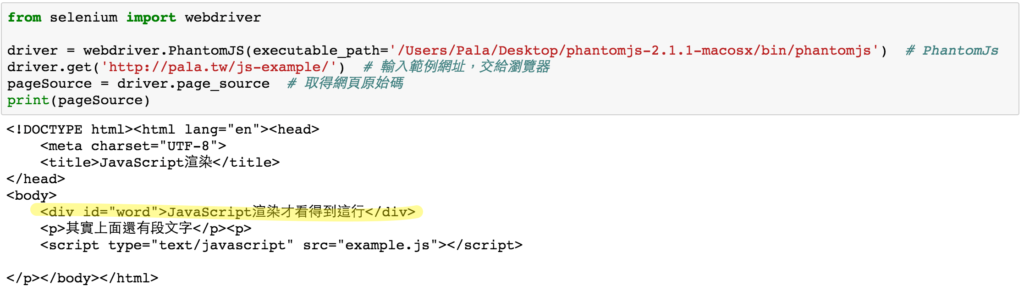
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path=r'請輸入路徑') # PhantomJs
driver.get('http://pala.tw/js-example/') # 輸入範例網址,交給瀏覽器
pageSource = driver.page_source # 取得網頁原始碼
print(pageSource)
driver.close() # 關閉瀏覽器內容完整顯示出來囉。
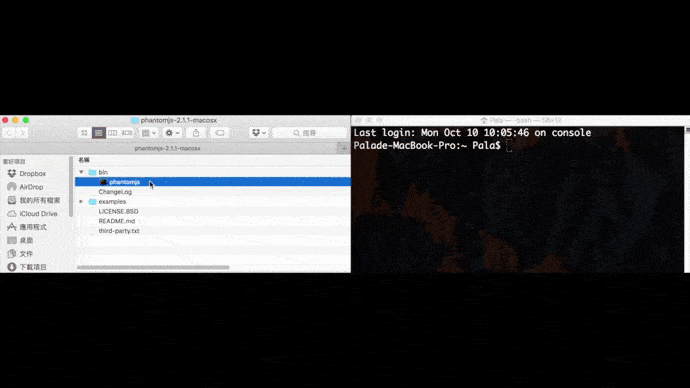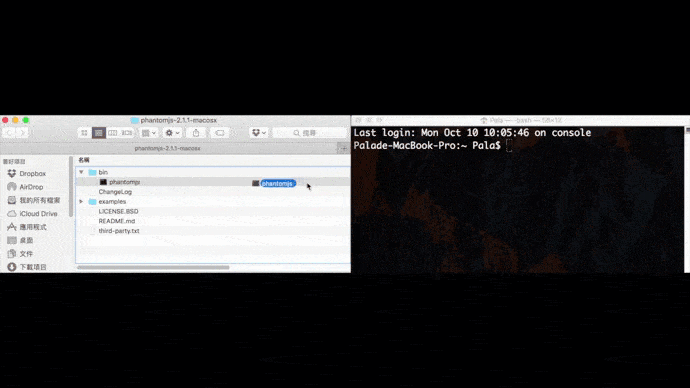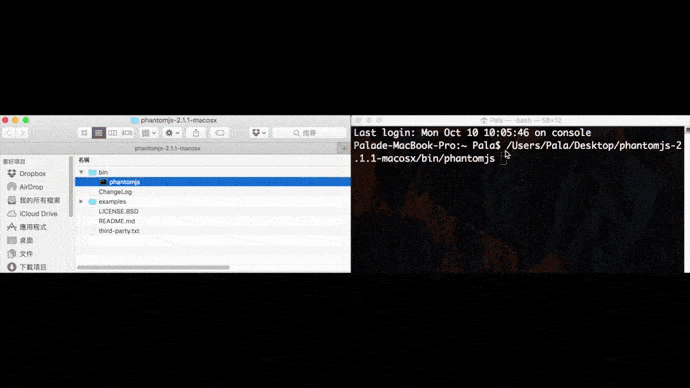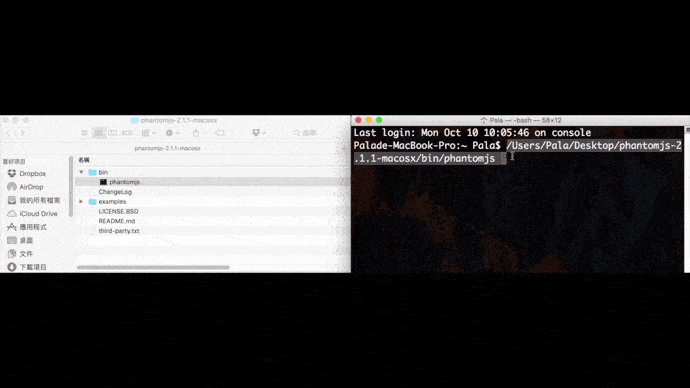
求救求救路徑怎麼找
Mac打開terminal,Windows打開cmd,並把剛剛下載的瀏覽器驅動程式拖曳到裡面,就可以直接複製完整路徑。
元素選擇器
現在我們已經知道怎麼讀取網頁原始碼,接著就是跟爬蟲說我們需要的元素是哪個。
「蛤~我不懂HTML跟CSS,網頁原始碼我看不懂~~」
呆就補!接下來介紹常用的定位元素class跟id。
範例:辦公室的下午茶
請想像你身為辦公室的手搖杯飲料訂購對外窗口。
下午三點半,眼前正擺著剛送來的20杯手搖飲料,因為劇情需要,你想著這20杯飲料,不就像網頁上的20筆資料嗎?而每杯飲料上的標籤,例如去冰、半糖、微糖,正如資料上所貼的分類標籤class。
但因為字實在太小了,為了節省大家拿取的時間,你決定用筆在飲料上寫下每個人的名字id,啊,這杯是老闆的、這杯是Pala的…。
好的,從以上的例子我們可以知道分類標籤class是可以重複出現的,就像很多杯飲料都會出現半糖;而id是唯一的,可以是名字、或是其他方便識別的內容。
要如何觀察定位元素呢?
請在辦公室的下午茶網頁上點右鍵,選擇檢查,點觀察器後指定元素:
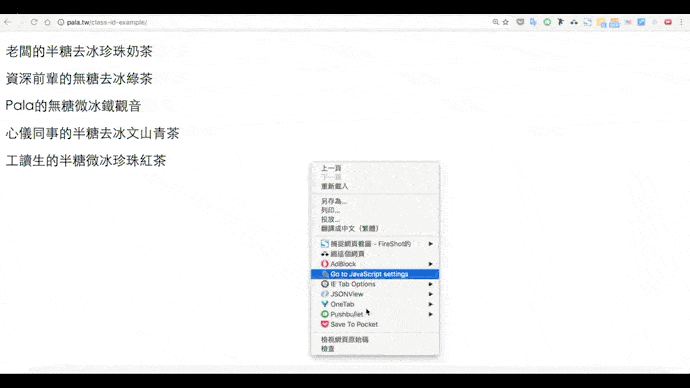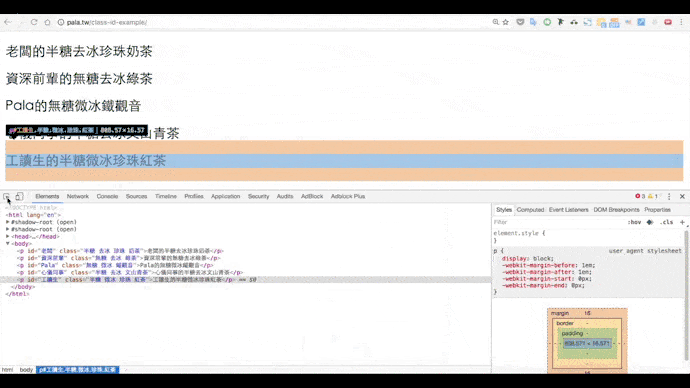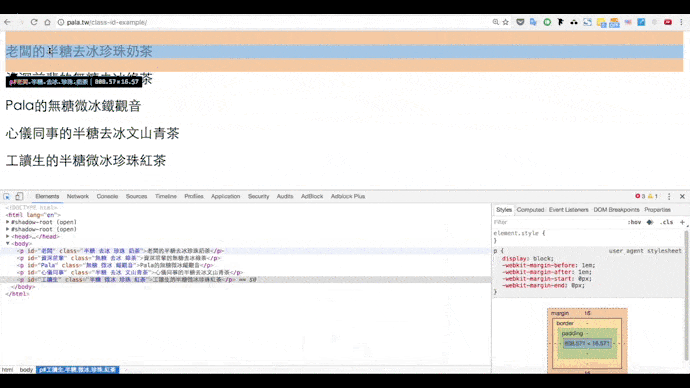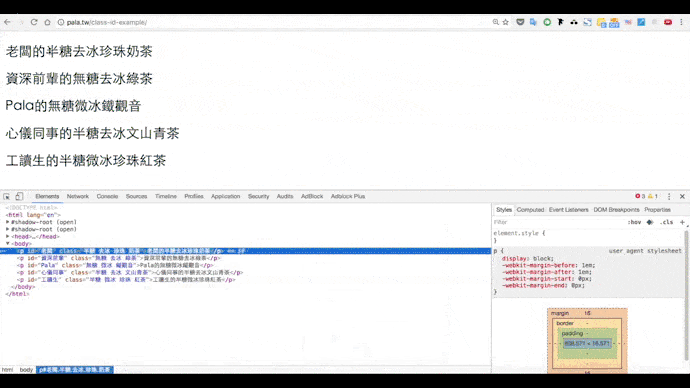
我們可以看到網頁原始碼如下:

選擇class,要在開頭加上句點.,例如.半糖;選擇id時,則要在前面加上井字號#,#老闆、#Pala,直接複製貼上這個程式碼試試看:
import requests
from bs4 import BeautifulSoup
tag = input("請輸入定位元素,class前面加上.,id前面加上# ")
res = requests.get('http://pala.tw/class-id-example/')
soup = BeautifulSoup(res.text, "lxml")
for drink in soup.select('{}'.format(tag)):
print(drink.get_text())起手式取得網頁原始碼,定位元素後交給BeautifulSoup處理,印出資料,結束!最常用的流程你現在已經會囉!

學習資源
關於BeautifulSoup的教學文,推薦靜覓的Python爬蟲利器二之Beautiful Soup的用法;而在後續學習Regular expression(正規表達式),Regex101會是個好幫手。
如果想要比較有系統的掌握,可以免費選修Coursera上的利用 Python 存取網路資料;想要透過範例學習新技巧,請參考大數學堂教學影片。
關於書籍,非常推薦Python網絡數據採集,很全面的介紹了爬蟲基礎概念,後來的繁體書名叫《網站擷取:使用Python》。我另外還有買一本Selenium 2自動化測試實戰,方便查閱,繁體書名為《不止是測試:Python網路爬蟲王者Selenium》,但沒有細看。

希望這兩篇文章,透過許多短片的輔助說明,可以幫助大家更理解爬蟲的基礎概念:)
附錄 前篇程式碼
認識網路爬蟲:解放複製貼上的時間的範例。
Google搜尋漫畫《蟲師》的結果筆數
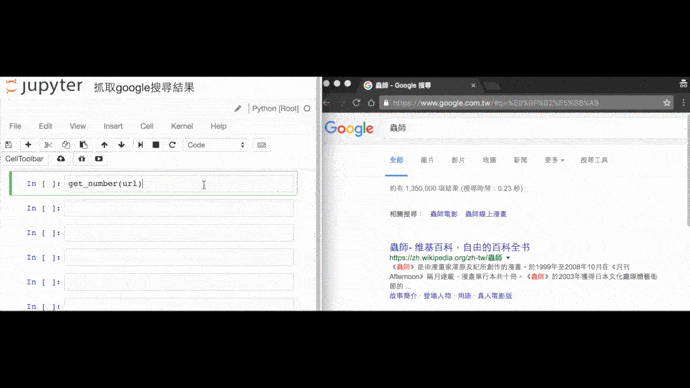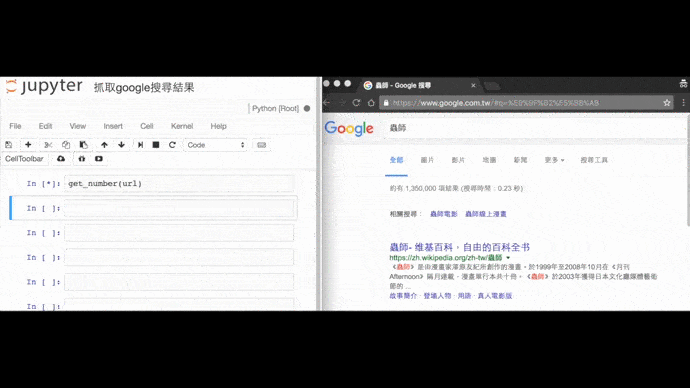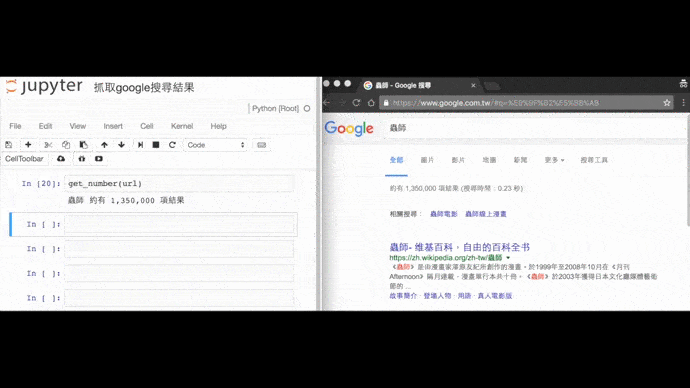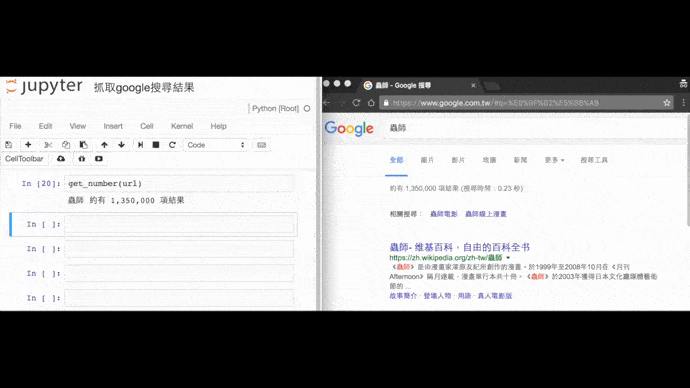
from selenium import webdriver
from bs4 import BeautifulSoup
url = 'https://www.google.com.tw/#q=%E8%9F%B2%E5%B8%AB'
driver = webdriver.PhantomJS(executable_path=r'請輸入路徑') # PhantomJS
driver.get(url) # 把網址交給瀏覽器
pageSource = driver.page_source # 取得網頁原始碼
soup = BeautifulSoup(pageSource, 'lxml') # 解析器接手
result = soup.select('#resultStats')[0].get_text() # 「約有 1,550,000,000 項結果」
print('蟲師', result)捲動瀑布流網頁,捲動的寫法
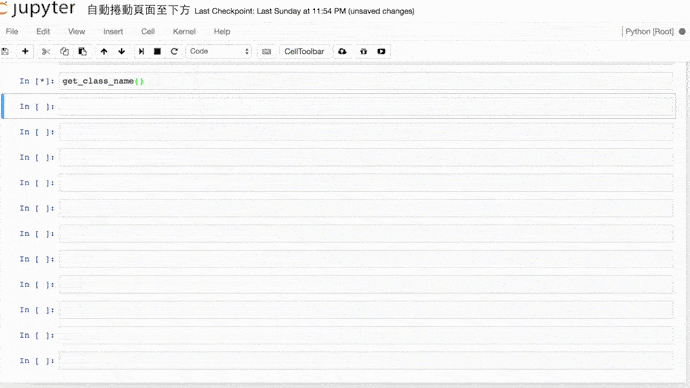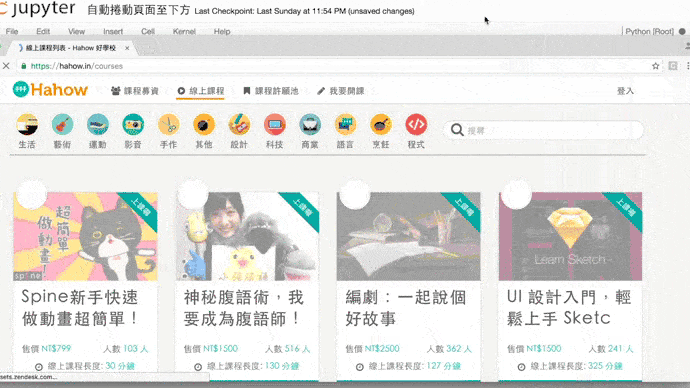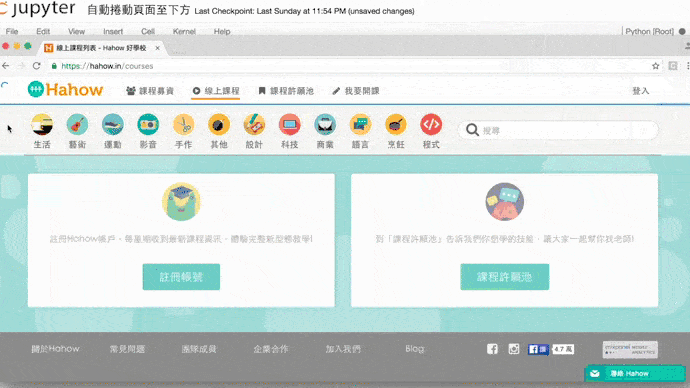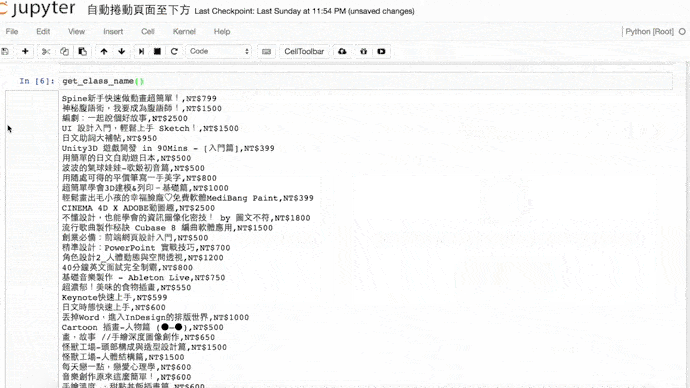
import time
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome(executable_path=r'請輸入路徑') # chrome瀏覽器
time.sleep(3)
driver.get('https://hahow.in/courses')
for i in range(10): # 進行十次
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);') # 重複往下捲動
time.sleep(1) # 每次執行打瞌睡一秒
driver.close() # 關閉瀏覽器全螢幕截圖
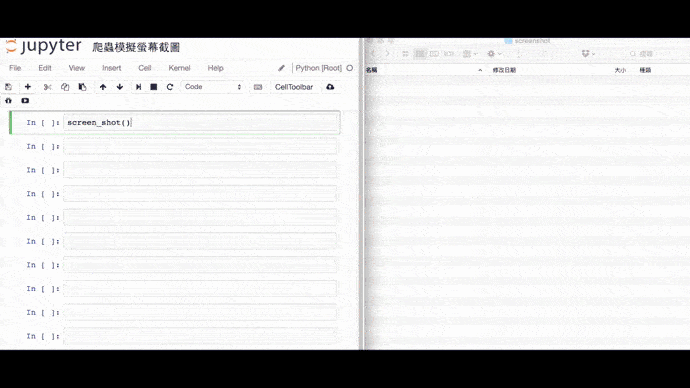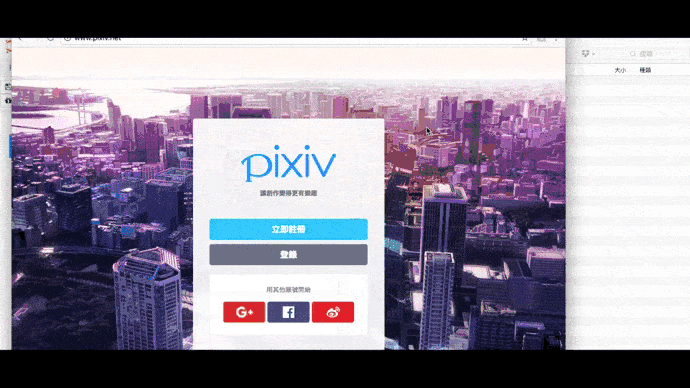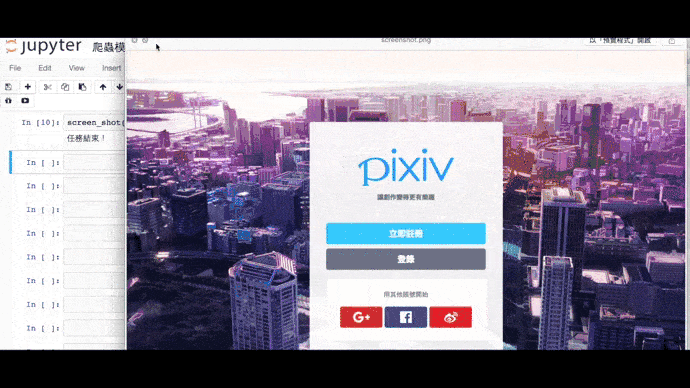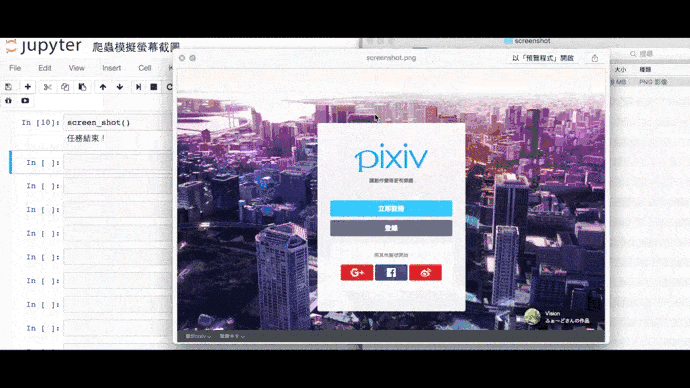
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r'請輸入路徑')
driver.get('http://www.pixiv.net/')
driver.save_screenshot('儲存位置/檔案名稱.png') # 保存截圖
driver.close()上篇:認識網路爬蟲:解放複製貼上的時間。
下篇:瀏覽器內的爬蟲初體驗。



